Background
The past years have shown that risk perception and risk communication are key issues in today’s societies. A number of voices have argued for the need to understand and estimate the public’s risk perceptions in many domains to better target specific interventions and help both laypeople and policy-makers make better, informed decisions, for example, when fighting global pandemics or climate change (e.g., Jenny & Betsch, 2022).
The Risk Hackathon aimed to provide a training opportunity in data analytics while showcasing ongoing work on risk perception by the Center for Cognitive and Decision Sciences. The hackathon proposed a set challenges linked to analysing a new data set on risk perception and evaluating the performance of novel models to predict risk perception.
The hackathon used data from a pre-registered study by Hussain et al. conducted in 2022 designed to compare the performance of the classic psychometric paradigm (Fischhoff et al., 1978) against novel models that rely on language embeddings (e.g., Bhatia, 2019). In this context, embeddings refer to vector representations of words obtained from natural language processing models trained on large amounts of text data or other data sources (e.g., free associations).
The Hussain et al. study involved asking thousands of participants to rate over 1000 words or terms (e.g., handgun, vaccination, artificial intelligence) concerning their perceived risk, with each word being rated on a scale of -100 (safe) to +100 (risky). The same words were also rated on 9 (psychometric) dimensions concerning, for example, whether the risk is typically fatal, controllable, voluntary, etc. The ratings from several respondents were averaged to create an average risk and psychometric ratings. These average risk ratings were utilized in the hackathon to understand average risk perception for different risks and compare the predictions of different models of risk perception.
Hackathon
A hackathon is a group event that gets individuals to work on a common problem using code. In the CDS Risk Hackathon participants were asked to answer a number of questions pertaining to how people perceive risks. The specific questions and data descriptors are provided here. The participants were organized intro groups of 4 to 5 people and collaborated to produce answers to the challenges in the form of data visualizations in R. CDS members provided training prior to the hackathon in the form of an R refresher course in the morning of the event. After the hackthon event, participants discussed their experience over drinks 🍻 and pizza 🍕.
Results
The results presented below are a subset of the data visualizations produced by the hackathon participants and are used to give an idea of the sort of insights generated by the hackathon. The full analysis of the data used will be provided in a scientific manuscript (Hussain et al., in preparation).
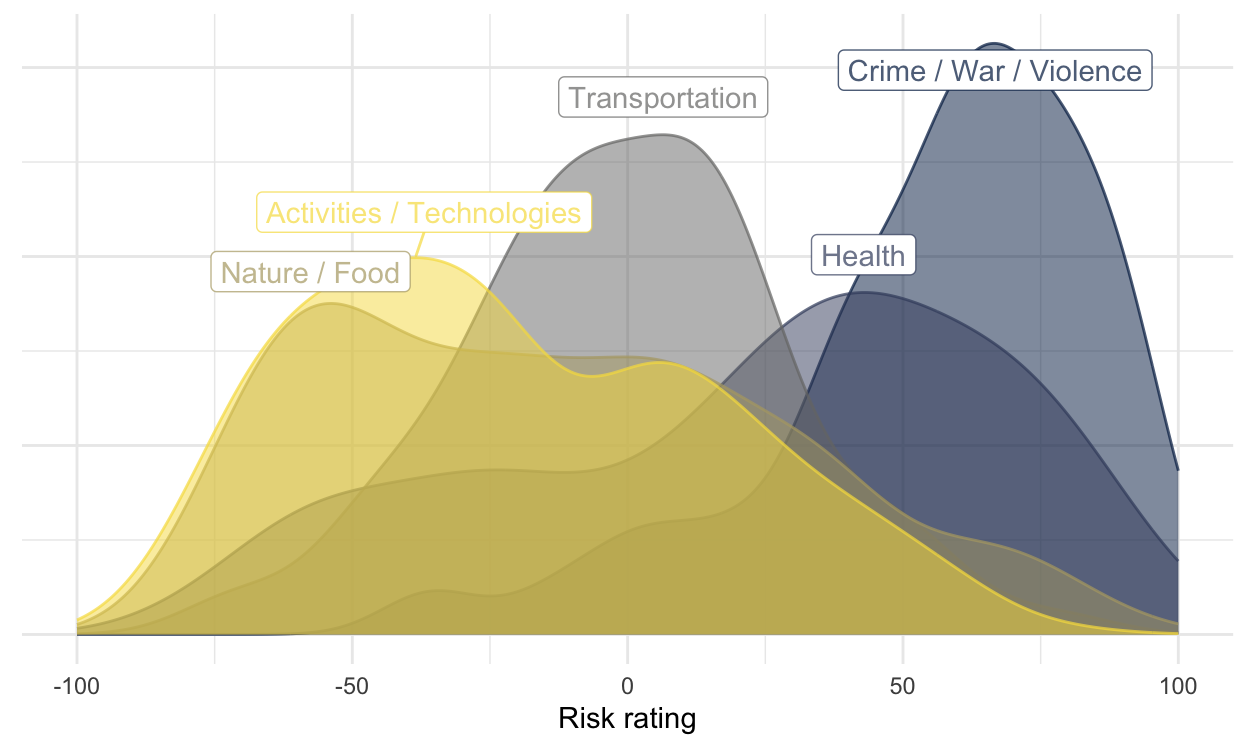
Items related to crime, war, and violence, are seen as most risky
Many of the words (i.e., events or actions) rated as most risky have to do with crime, war, or violence. A number of health-related items and technologies are also seen as quite risky on average. Some hackathon participants used density plots to obtain an overview of risk ratings that make clear the average differences between these different types of risks.
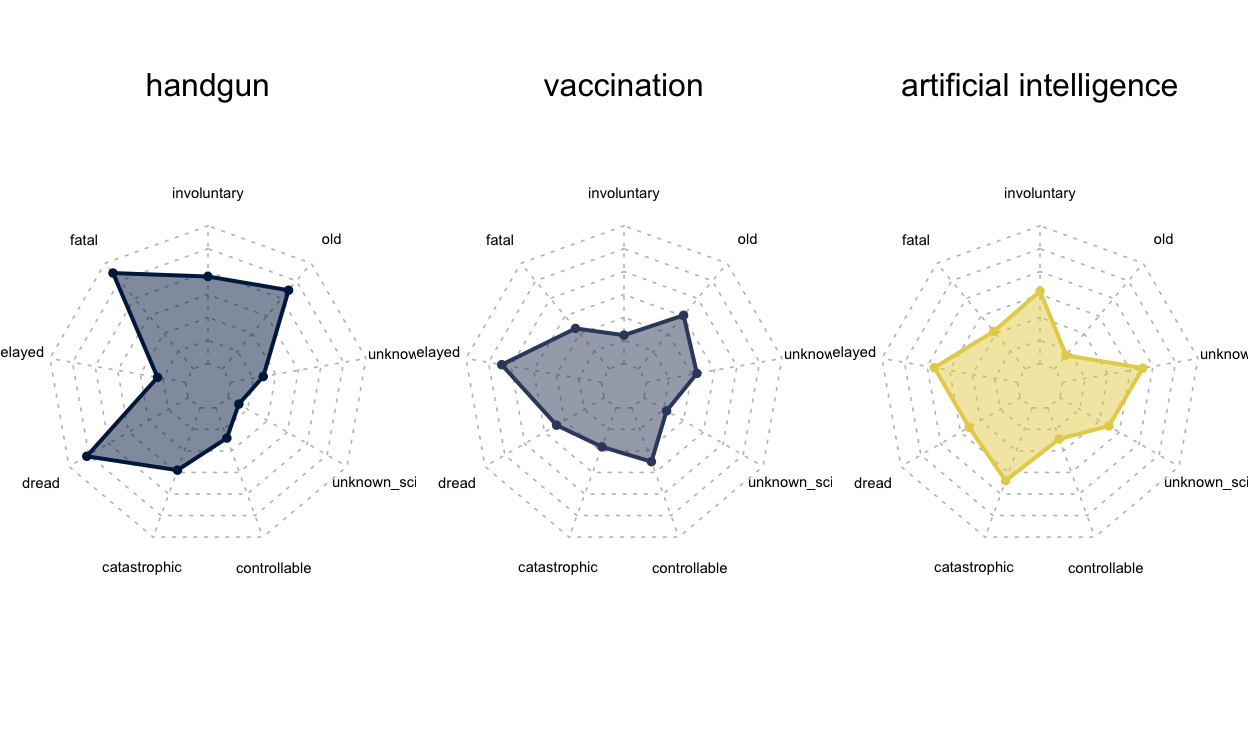
Items differ considerably in their psychometric profile
The different types of risks have different profiles concerning the 9 psychometric dimensions that were considered in the study in line with past work (cf. Bhatia, 2019; Fischhoff et al., 1978). Some hackathon participants used radar charts to explore the profiles of different types of risks, including older ones, like handgungs, and newer ones, like artificial intelligence.
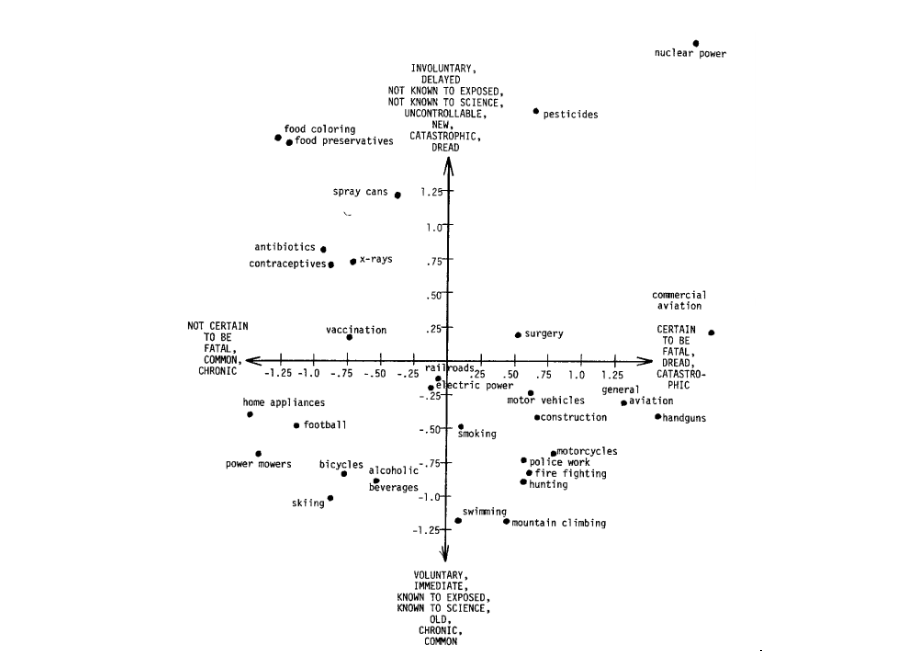
Replicating the two-dimensional representation of risk perception
Participants were asked to replicate the classic two-dimensional visual representation of risks first obtained by Fischhoff et al. (1978).
Most participants created a modern version of the plot - including 1004 risks - and highlighting those that were also present in Fischhoff et al. (1978).
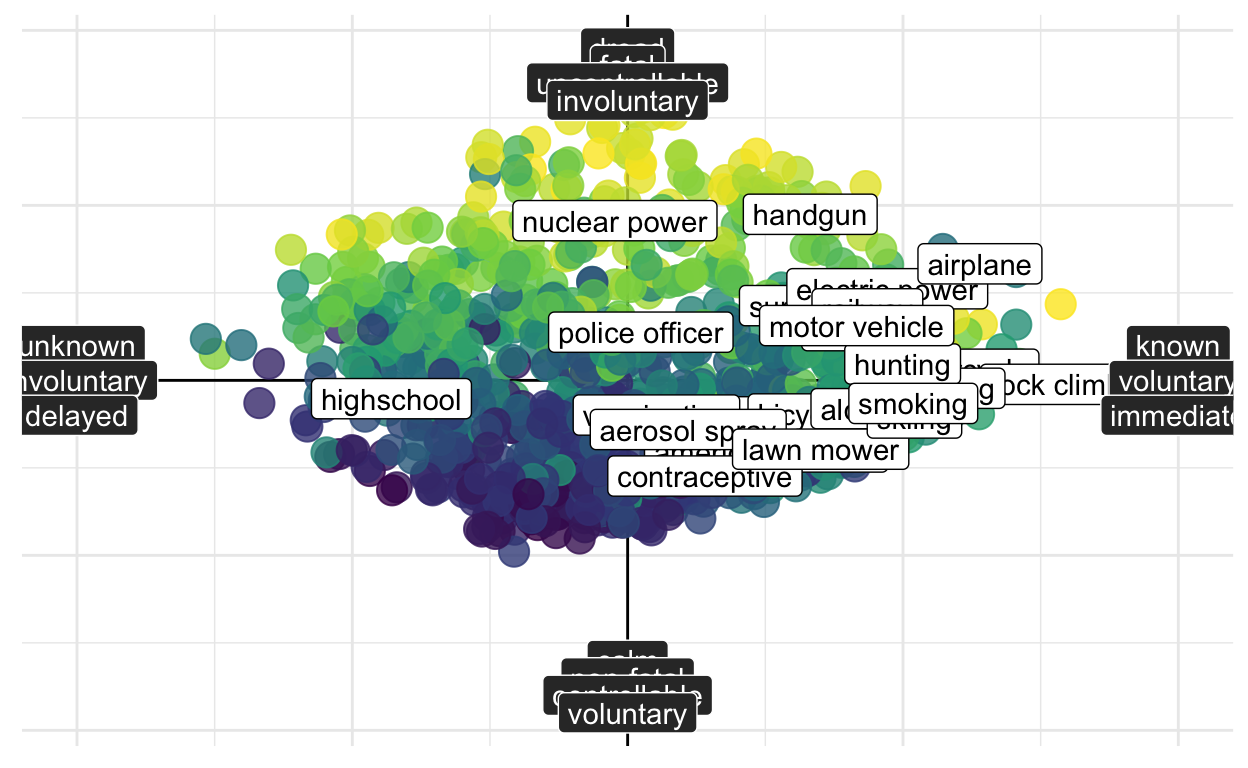
The results question the two-dimensional representation of risk perception
Fischhoff et al. (1978) conduct a principal component analysis on the psychometric items and concluded that risk could be accounted for by a two-dimensional representation. However, the novel results by Hussain et al. (2022) suggest that a two-dimensional representation may not be the best way to think about this larger set of risks.
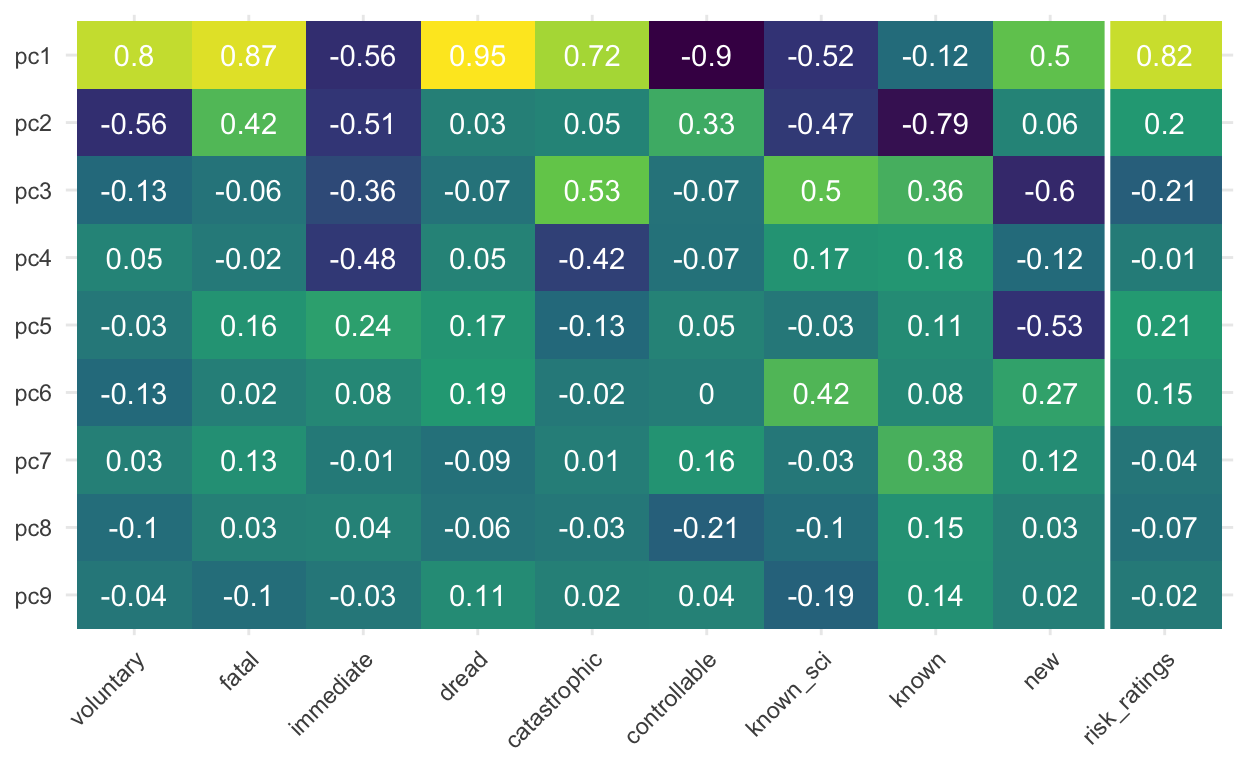
As can be seen in the tile plot below, the first principal component (pc1) is highly correlated with the risk ratings (r = .81) but a number of additional components (pc3, pc5, pc2) show similar correlations to risk ratings (r ≈ .2). This questions a two-dimensional representation of risks as initially proposed by Fischhoff and colleagues.
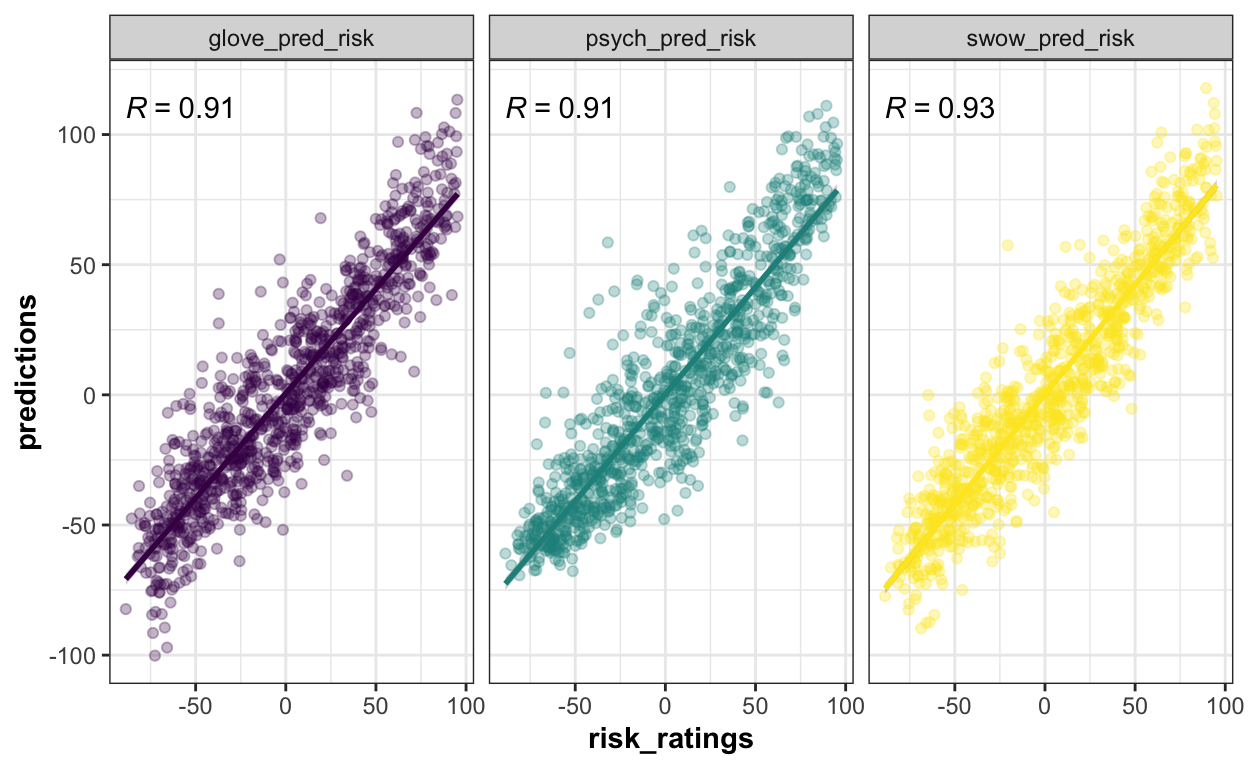
Embedding and psychometric models show similar performance levels
The groups were asked to compare the results of different prediction models. As it stands, the new models do not seem to beat the psychometric paradigm. This suggests that the features identified by Fischhoff and colleagues are important predictors of risk perception. It will be interesting to assess to what extent future, more sophisticated embeddings and ensemble models are able to beat this classical model from the psychology of risk perception.
Limitations and Future Directions
The CDS Risk Hackathon has mostly a pedagogical character and, consequently, focused providing participants with an opportunity to explore a novel data set. Nevertheless, some of the limitations of the data and analyses conducted should be emphasized.
While great care was taken to ensure high reliability of the mean risk ratings and psychometric dimensions, the data used are averages of small numbers of English-speaking participants and, therefore, are not representive of global views of risk perception. Past work suggested that are important individual and group differences in risk assessments and it could be important to assess these to understand global risk perceptions as well as phenomena like risk polarization (cf. Wulff & Mata, 2022).
Despite the data set of words representing the largest set of risks collected, there are nevertheless a number of risks that have not been considered but that are very relevant to public health and safety (e.g., cyberfraud, microplastic, fusion). Future work may consider yet additional sources of risk by pooling experts and laypeople’s thoughts on relevant risk sources.
The models considered in the prediction exercise are only a subset of possible models and more sophisticated ones may yet be developed. For example, ensemble models that make use of several embeddings can be used, which is something that will be explored in Hussain et al. (in preparation). More generally, the models considered were obtained from single words or bigrams and did not consider full sentences or larger amounts of text that can be important for contextualizing certain risks.
Conclusion and Testimonials
Overall, the event was a success in that it helped participants reflect on the topic of risk perception while providing training on data wrangling and visualization skills. We are very happy to have received some positive testimonials from a number of participants!
“I really liked the close group collaboration and the fact that we had experienced team members who could help us.”
“I learned a lot as a R Novice thanks to the instructors’ guidance”
“It’s a cool idea to split in different groups with one dataset and the same task. As in the end, we have different outcomes of visualizations and insights.”
“the pizza was great :))”
Figure 1: Intro/Conclusion Presentation
References
Bhatia, S. (2019). Predicting risk perception: New insights from data science. Management Science, 65(8), 3800–3823. https://doi.org/10.1287/mnsc.2018.3121
Fischhoff, B., Slovic, P., Lichtenstein, S., Read, S., & Combs, B. (1978). How safe is safe enough? A psychometric study of attitudes towards technological risks and benefits. Policy Sciences, 9(2), 127–152. https://doi.org/10.1007/BF00143739
Jenny, M. A., & Betsch, C. (2022). Large-scale behavioural data are key to climate policy. Nature Human Behaviour, 6(11), 1444–1447. https://doi.org/10.1038/s41562-022-01479-4
Wulff, D. & Mata, R. (2022). On the semantic representation of risk. Science Advances, 8. https://science.org/doi/10.1126/sciadv.abm1883