Deep feedforward
| Introduction to Neural Networks |

|

Overview
By the end of this practical you will know how to:
- Use
Kerasto build deepforward neural networks. - Use
Kerasto fit and evaluate deepforward neural networks. . - Use
Kerasto optimize the predictive performance of deepforward neural networks.
Tasks
A - Setup
Open your
neuralnetsR project.Open a new R script. Save it as a new file called
deep_feedforward_practical.Rin the2_Codefolder.Using
library()load the the packagestidyverseandkeras
# install.packages("tidyverse")
# install.packages("keras")
# Load packages necessary for this exercise
library(tidyverse)
library(keras)- Run the code below to load the
fashion.RDSdataset as a new object.
# MNIST fashion data
fashion <- readRDS(file = "1_Data/fashion.RDS")- Take a look at the contents of the
fashionobject usingstr(). You will see a list with two elements namedtrainandtest, which consist of two elementsx(the images) andy(the item depicted).
# Inspect contents
str(digit)- Now
source()thehelper.Rfile in your2_Codefolder.
# Load helper.R
source("2_Code/helper.R")B - Data preprocessing
- Before you get started modeling the data using neural networks, some preprocessing needs to be done. First, split into its individual elements that is into
imagesanditemsseparately for training and test. Use the code below.
# split digit train
c(fashion_train_images, fashion_train_items) %<-% fashion$train
# split digit test
c(fashion_test_images, fashion_test_items) %<-% fashion$test- Now use the
array_reshapefunction to serialize the images of both training and test, such that every image is a vector of28*28=784elements (and resulting object a matrix with that many columns). Use the code below.
# reshape images
fashion_train_images_serialized <- array_reshape(fashion_train_images, c(nrow(fashion_train_images), 784))
fashion_test_images_serialized <- array_reshape(fashion_test_images, c(nrow(fashion_test_images), 784))- Also normalize the images by dividing them by 255, the maximum greyscale value.
# rescale images
fashion_train_images_serialized <- fashion_train_images_serialized / 255
fashion_test_images_serialized <- fashion_test_images_serialized / 255- Now, expand the criterion, such that instead of a single integer, the criterion is a one-hot coded vector, with a
1sitting in the position of the integer and0s otherwise.
# expand criterion
fashion_train_items_onehot <- to_categorical(fashion_train_items, 10)
fashion_test_items_onehot <- to_categorical(fashion_test_items, 10)- Use
head(fashion_train_items_onehot)to inspect the first few rows and compare them tohead(fashion_train_items). Do things line up?
C - Illustrate
- Before visualizing the images, create a vector that contains the labels for the 10 different fashion items.
# fashion items
fashion_labels = c('T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot')- Now use the
plt_imgs()function, which you have loaded earlier with thehelper.Rscript, to illustrate the images. You have add a1, because the indices infashion_train_itemsstart at0.
# rescale images
plt_imgs(fashion_train_images[1:25,,],fashion_labels[fashion_train_items[1:25]+1])D - Build network
- Alright, use
keras_model_sequential()to start building a network.
# begin building network
net <- keras_model_sequential()- Ok, for now, let us build the most simple model with single input and output layers. To do this, add a single
layer_dense(). Inside the function you will have to specify three arguments:input_shapeandactivation. For a moment, think about what values to use for these three given the kind of data that you wish to model. The answers come in a sec.
# add layer
net %>% layer_dense(
input_shape = XX,
units = XX,
activation = "XX"
)The correct solutions are
input_shape = 784to specify that there must be784input nodes, one for each pixel,units = 10to specify that there must be 10 different output nodes, andactivation = 'softmax'to specify that the final activation should be a probability that sums to1across all output nodes. After you have entered these values, usesummary(net)to see the model information.Take a look at the
Param #column in the print out. Why is the number7850rather than7840 = 784 * 10? Any ideas?Yes,
kerasautomatically adds a biases to each node in a layer.
E - Compile network
- Use
compile()to compile the network. You will need to specify at least two arguments:optimizerandloss. Think about what we’ve used in the presentation. Would the same values make sense here?
# loss, optimizers, & metrics
net %>% compile(
optimizer = 'XX',
loss = 'XX',
metrics = c('accuracy')
)- Yes, the fashion dataset has exactly the same properties as the digit dataset. So, plug in
optimizer = 'adam'andloss = categorical_crossentropyand run the chunk. You see I’ve also added'accuracy'as an additional metric, which can be useful to track during fitting, as it is much easier to interpret thancrossentropy.
F - Fit network
- You’ve come to the point where the magic happens. Fit the network using
fit(). Specify, the argumentsx,y,batch_size, andepoch. Think for a moment, what the appropriate values for these arguments could be.
# loss, optimizers, & metrics
history <- net %>% fit(
x = XX,
y = XX,
batch_size = XX,
epochs = XX
)The arguments
xandyspecify the training features and training criterion, respectively, sox = fashion_train_images_serializedandy = fashion_train_items_onehot. The argumentsbatch_sizeandepochscontrol how often the weights will be updated and for how many iterations of the data set. Useful (and somewhat arbitrary) values arebatch_size = 32andepochs = 10. Use these values and then run the chunk.The
fitfunction automatically provides with useful information on the progression of fit indices. You can additionally use thehistoryobject to get the same illustration to create aggplot. Runplot(history) + theme_minimal(). When you inspect the plot, what tells you that the network indeed has learned? And how good is the final performance of the network?The network has learned, which can be gathered by the decrease in
lossand the increase inaccuracy. The non-linear pattern is very characteristic, almost always most of the gains are achieved in the first epoch or two. To get accurate values on the final performance you can simply printhistory. What do you think, how well will this network perform in predicting fashion items out-of-sample? Find out in the next section.
G - Evaluate network
- Evaluation of the performance of neural networks should always only be done on the basis of true prediction, using data that was not used during training. Evaluate the networks predictive performance using
evaluate()while supplying the function with the test images and items.
# evaluate
net %>% evaluate(XX, XX, verbose = 0)The network is slightly worse than in training, but still pretty good given that guessing performance is only
10%accuracy. This, again, is very characteristic. In machine learning “simple” models often get a long way towards the desired level of performance. Though, one might question whether a model with 750 parameters can still be considered “simple”.Compare the predictions made by the network with the actual fashion labels. Do you note any patterns? Can you maybe understand the errors that the network has made.
# compare predictions to truth
pred = net %>% predict_classes(fashion_test_images_serialized)
table(fashion_labels[fashion_test_items+1], fashion_labels[pred+1])H - Build & evaluate deeper network
- Build a deeper neural network with two hidden, fully-connected layers with 256 and 128 units, respectively, and a
'relu'activation function. See template below. The final layer will again be the output layer and must be supplied with the same values as before. Plot the summary at the end.
# initialize deepnet
deepnet <- keras_model_sequential()
# add layers
deepnet %>%
layer_dense(input_shape = 784, units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX")
# model information
summary(deepnet)How many parameters are there now in the network?
A whole lot more parameters. There are more than 300 times as many parameters as before. Let’s see what this network can achieve. Compile and train the network using the exact same steps as before and then evaluate the network on the test data. The only change in the code you need to make is to replace
netwithdeepnet.The test performance has improved by about 7% points. Not bad. Also the drop from fitting to testing performance is small suggesting minimal overfitting of the data. Let’s the see how far we can take it. Let’s build a real deep network
I - Build & evaluate real deep network
- Build a real deep network with two additional 256-node layers, two additional 128-node layer, and three additional layers 64-node layers. In the end, there should be three layers of each kind, sorted, as before, in descending order of the number of nodes. Take a look at the summary.
# initialize realdeepnet
realdeepnet <- keras_model_sequential()
# add layers
realdeepnet %>%
layer_dense(input_shape = 784, units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = XX, activation = "XX")
# model information
summary(realdeepnet)The number of parameters in network only increased by a factor of 2, because the lion share stems from the weights between the input and the first hidden layer, which remained unchanged. Nonetheless, there is reason to believe that this network fares differently. Try it out using the exact same steps as before.
The model did not fare a whole lot better. The fit performance increased a bit, but the predictive accuracy more or less remained constant. Fit the model again. To do this you can simply run the fit function again, which will lead to a continuation of training from where training ended before. After training has finished, evaluate the predictive accuracy again.
Not all too much happening. Though, both fitting and prediction performance went up by another notch. This is again characteristic of neural networks. To really max out on performance, many epochs of training will often be necessary. However, at the same time risks to give the model opportunity to overfit the data.
J - Battling overfitting
- To begin with create a
crazycomplexnetwhich should have twice as many nodes in the first hidden layer than there are input nodes. Add as many hidden layers as you like and then run the network for20epochs for a batch size of100and evaluate the network’s performance.
# initialize crazycomplexnet
crazycomplexnet <- keras_model_sequential()
# add layers
crazycomplexnet %>%
layer_dense(input_shape = 784, units = 1568, activation = "relu") %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dense(units = 10, activation = "softmax")
# model information
summary(crazycomplexnet)- This should have upped the fitting performance, but possibly hurt the prediction performance. See whether adding
layour_dropout(rate = .3)in between thelayer_dense()helps preserve some more of the fitting performance for test. Layer dropout sets the activation of a random subset of nodes to zero, which effectively eliminates momentarily the weights emitting from the node and, thus, constrains model flexibility.
# initialize crazycomplexnet
crazycomplexnet <- keras_model_sequential()
# add layers
crazycomplexnet %>%
layer_dense(input_shape = 784, units = 1568, activation = "relu") %>%
layer_dropout(rate = XX) %>%
layer_dense(units = XX, activation = "XX") %>%
layer_dropout(rate = XX)
layer_dense(units = 10, activation = "softmax")
# model information
summary(crazycomplexnet)Resources
Cheatsheet
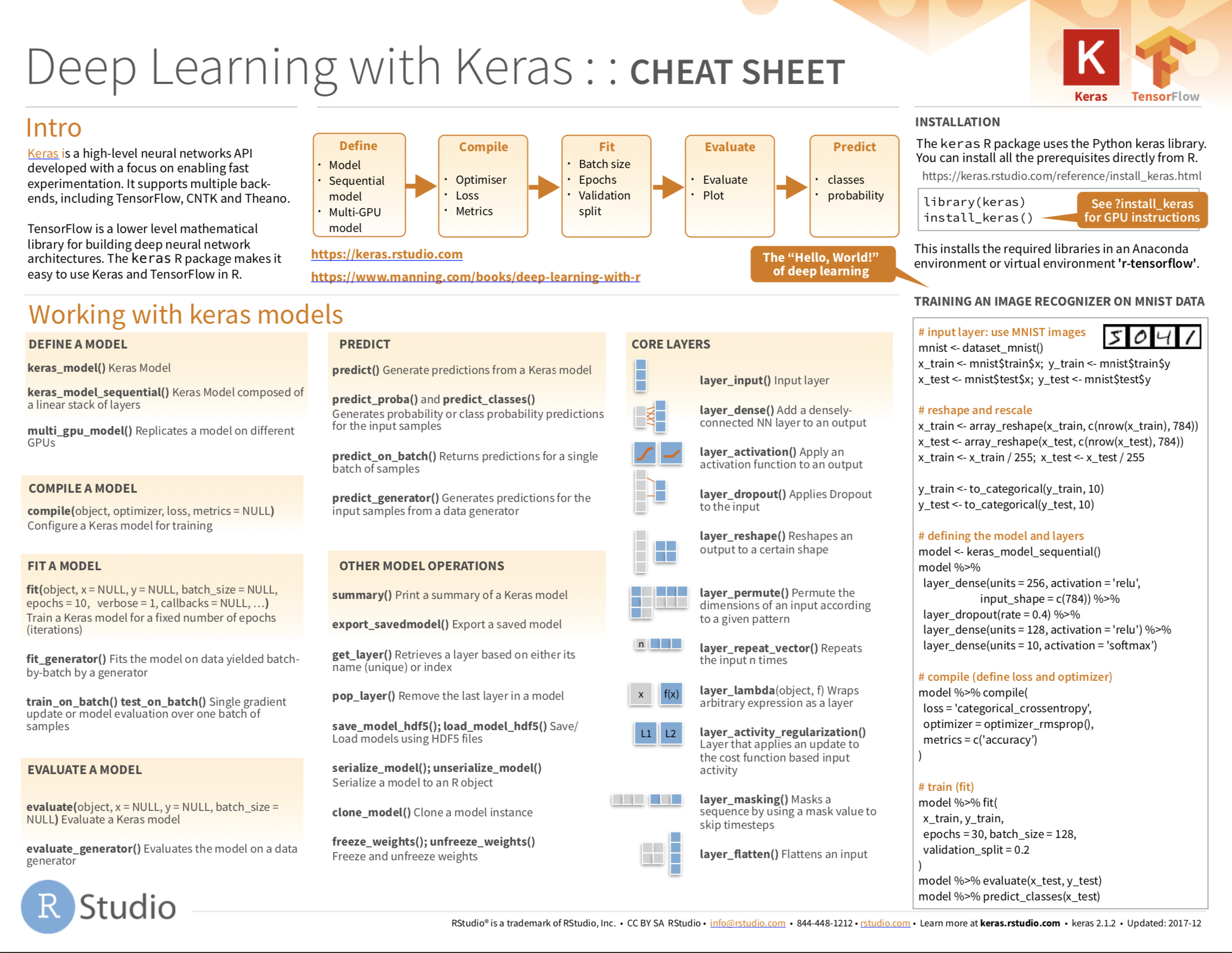
from github.com/rstudio